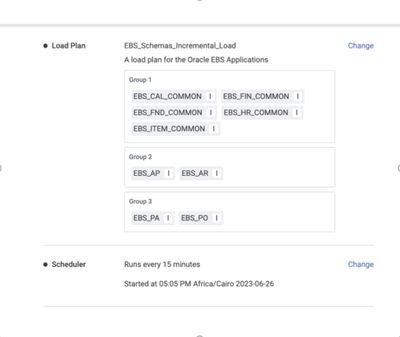
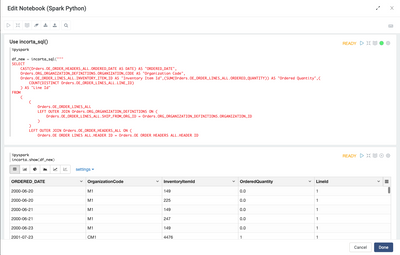
Handling Source Deletes Via Purge
When loading data incrementally, Incorta inserts new records and updates existing records that have already been loaded, but by default it does not delete records. Source systems like Oracle Cloud ERP, however, may allow users to delete data. This ...