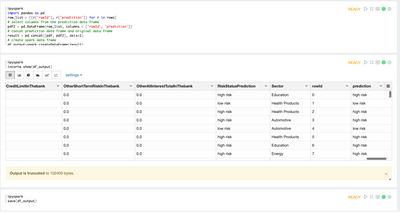
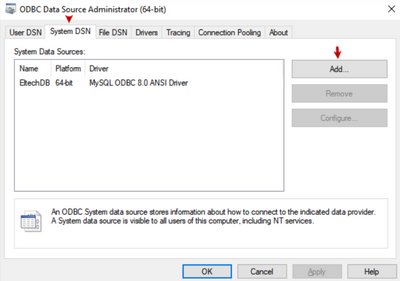
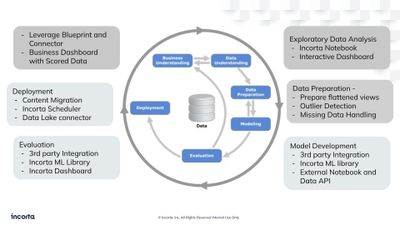
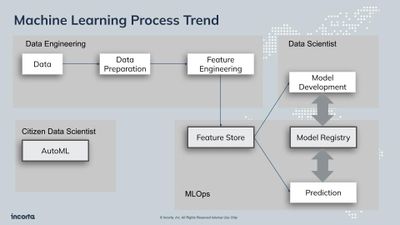
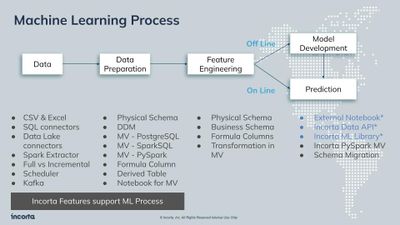
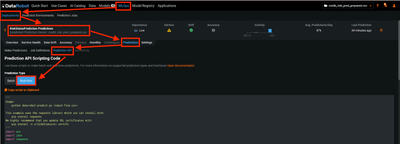
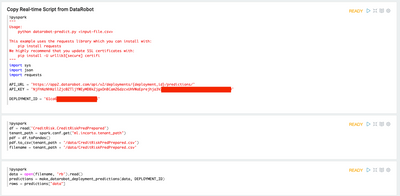
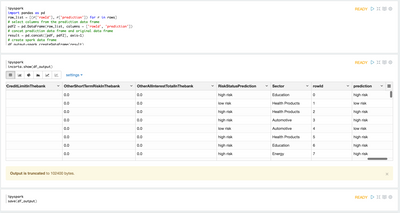
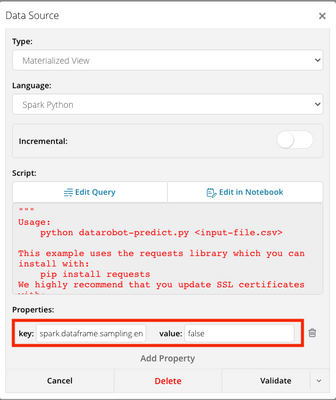
Data Harmonization for Multi-Source
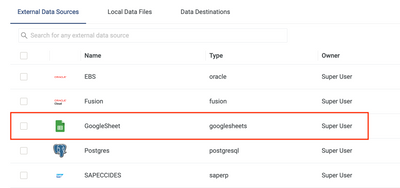
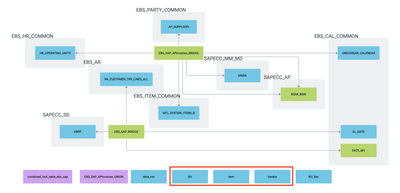
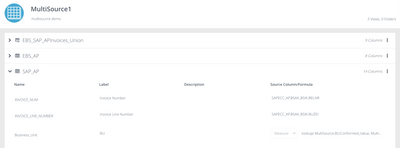
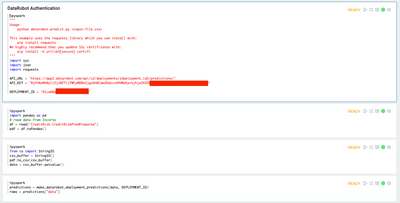
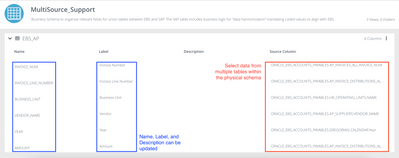
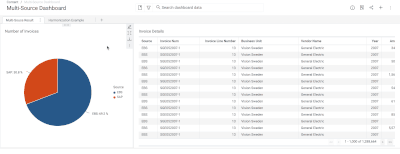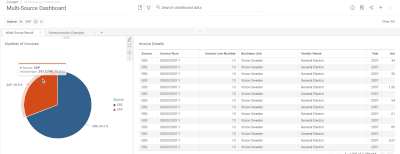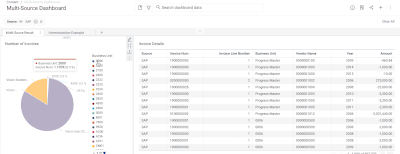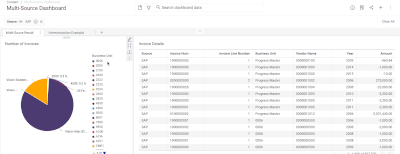
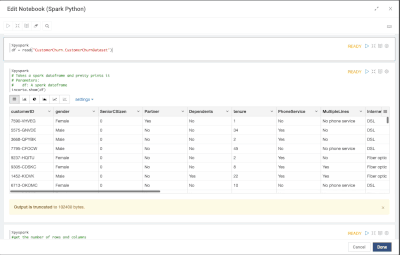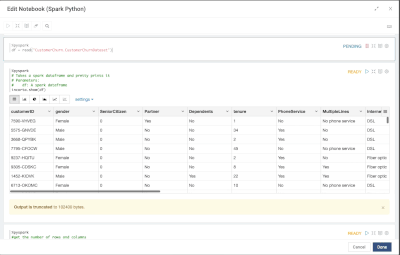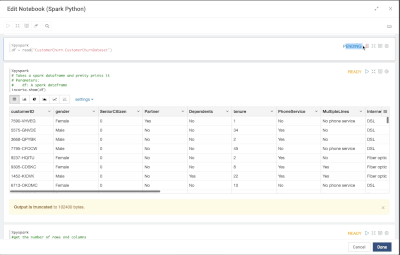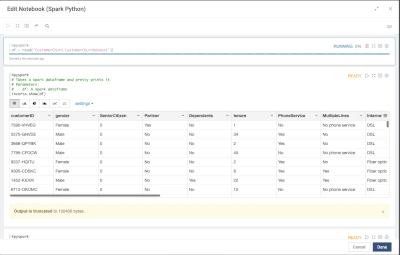
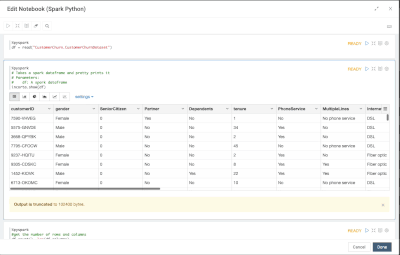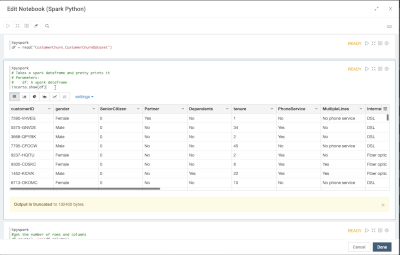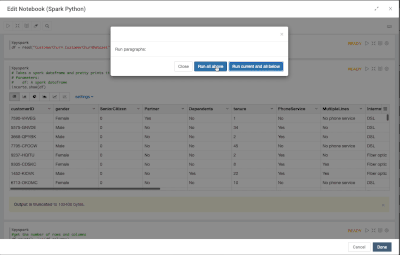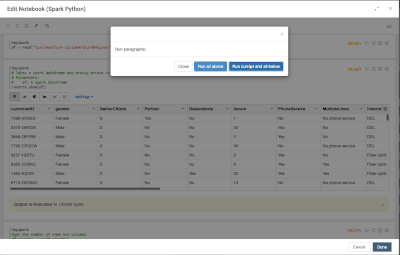
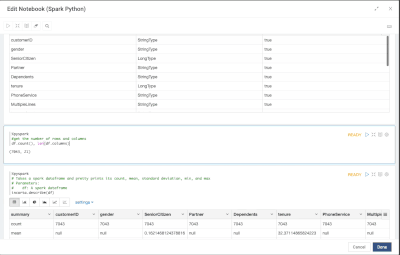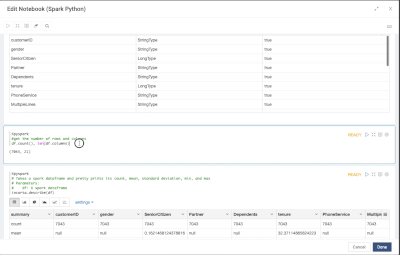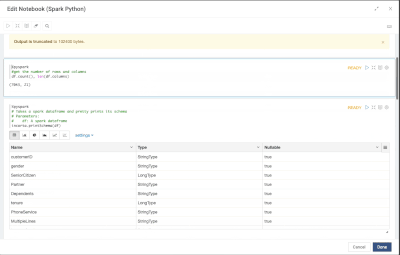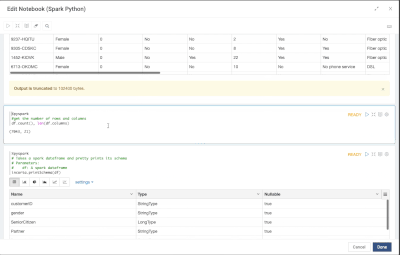
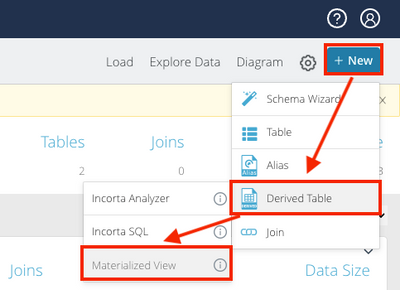
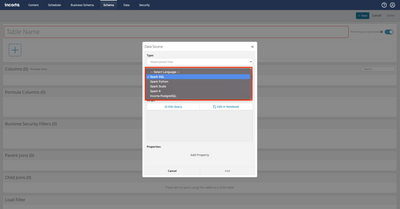
Introduction When creating visualizations based on multiple source systems, tables must be aligned to achieve a wholistic view of a business. For example, organizations that migrate from one ERP to another align invoice tables from each ERP to see al...